Learning Failure Prevention Skills for Safe Robot Manipulation
Abdullah Cihan Ak
Istanbul Technical University |
Eren Erdal Aksoy
Halmstad University |
Sanem Sariel
Istanbul Technical University |
2023 IEEE Robotics and Automation Letters
Abstract:
Robots are more capable of achieving manipulation tasks for everyday activities than before. However, the safety of manipulation skills that robots employ is still an open problem. Considering all possible failures during skill learning increases the complexity of the process and restrains learning an optimal policy. Nonetheless, safety-focused modularity in the acquisition of skills has not been adequately addressed in previous works. For that purpose, we reformulate skills as base and failure prevention skills, where base skills aim at completing tasks and failure prevention skills aim at reducing the risk of failures to occur. Then, we propose a modular and hierarchical method for safe robot manipulation by augmenting base skills by learning failure prevention skills with reinforcement learning and forming a skill library to address different safety risks. Furthermore, a skill selection policy that considers estimated risks is used for the robot to select the best control policy for safe manipulation. Our experiments show that the proposed method achieves the given goal while ensuring safety by preventing failures. We also show that with the proposed method, skill learning is feasible and our safe manipulation tools can be transferred to the real environment.
This research is funded by a grant from the Scientific and Technological Research Council of Turkey (TUBITAK), Grant No. 119E-436.
Approach:
We define safe robot manipulation as skill selection in real time from the
skill library consisting of a base skill to complete the task and
failure prevention skills to reduce failure risks. Skills
with the purpose of reaching a goal to complete a task are
defined as base skills (i.e., stirring or pouring). Skills with
the purpose of preventing failures define failure prevention
skills (such as prevention of sliding, overturning, or spilling).
A skill selection creates a hierarchy and becomes the higher
level, triggering the optimal skill from the skill library to
safely accomplish the task. The lower level of the hierarchy
is a skill library which is composed of base skills and failure
prevention skills. For each potential failure, a failure detection
and risk estimation model is defined to estimate the risk of the
failure happening in the near future. Failure prevention skills
are learned and added to the skill library to prevent potential
failures as illustrated at bottom.

Our main contributions are as follows:
- the formulation and implementation of a modular and hierarchical method for safe robot manipulation;
- enabling learning reusable failure prevention skills as
precautionary switching policies in a skill library for safe
manipulation;
- adapting to failures and augmenting incrementally;
- real world applicability by effective safety precautions in
the physical world.
Evaluations:
Failure Prevention Skills
Failure prevention skills are learned with preliminary information about the failure. We use an observable parameter to define the failure as it is outside of the expected range and define safety as it resides in the expected range. This failure representation is named risk estimation model.
A risk is a binary safety estimate (safe - risky) against a failure, and presents the probability of a failure to occur in the near future. is the observed parameter for failure . is the activation and is the deactivation thresholds. The interval between and prevents undesired fluctuations between states when the observed parameter is close to thresholds. Failures that are cover in this work are given below.
Learning a failure prevention skill is formulated as an MDP with a tuple: where is a continuous state, is a continuous action, is transition probability, is the reward and is the discount factor.
is the phase value representing the relative time of the execution, making the system time-variant.It is a value between , and updated with after each action.
Deep Deterministic Policy Gradients (DDPG) is used for optimization. Both actor and critic neural networks are designed with two linear feed-forward layers with 400 and 300 neurons and with ReLU activation layer in between. The networks are trained for 1500 episodes with 500 steps where the batch size is 128, learning rates are 0.0001 and discount factor is 0.99. For exploration, linearly decaying epsilon is used and the noise is modeled with Ornstein-Uhlenbeck process with parameters . Episodes are started with observing the corresponding failure.
Resulting skills are given below. In these videos, at start the robot moves to increase the risk of failure to occur and then switches to the corresponding failure prevention skill to prevent the failure to occur.
| πpslide |
πpoverturn |
πpspill |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Safe Robot Manipulation with Failure Prevention Skills
A skill library is initialized with the learned base skill
(). Then, learned failure prevention skills () are added to the skill library () augmenting
the base skill for safe robot manipulation. We use a rulebased
skill selection policy that selects a policy depending on the importance of failure which is determined by its effect on the task.
Note that, for a different setup, the importance of failures can
be different from what we present. For example, if the robot
stirs a pan on a stove, keeping the pan on the stove would be
more important than spilling the content.
A sample execution of the proposed method with for the stir task is given in the figure below. In the figure, 8 keyframes are given to explain the behavior of the robot.
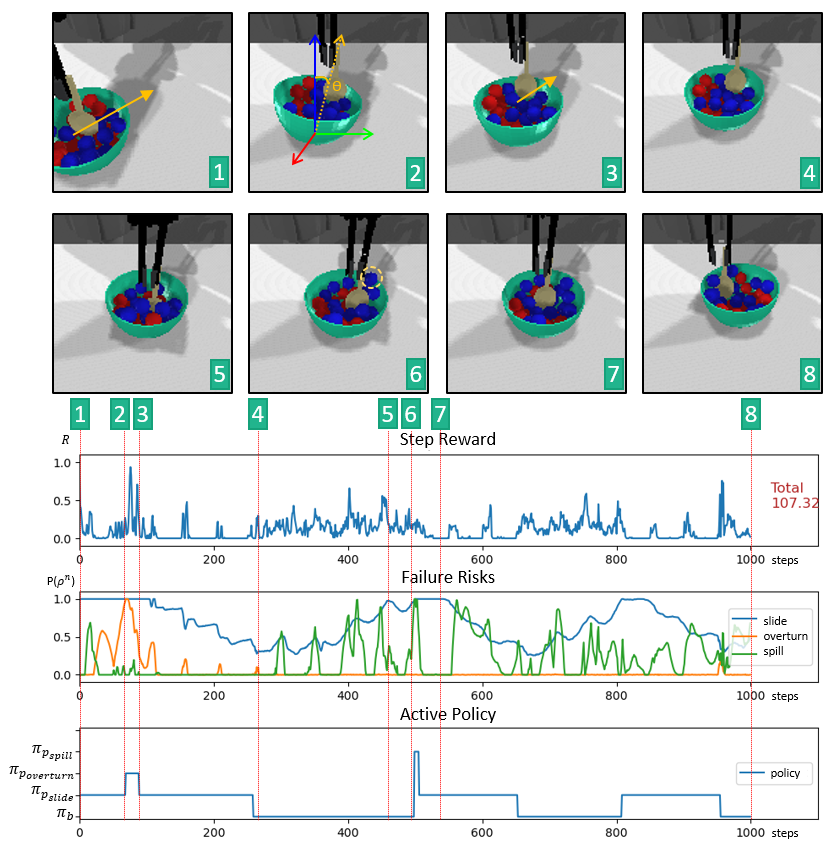 |
|
At the start(keyframe  ), the bowl is located away from the initial location therefore πpslide is selected to be executed. While the robot moves the bowl to the desired position using πpslide, the bowl is starting to overturn (keyframe ), the bowl is located away from the initial location therefore πpslide is selected to be executed. While the robot moves the bowl to the desired position using πpslide, the bowl is starting to overturn (keyframe  ) and the robot starts to execute πpoverturn because of the priorities defined for skill selection. After overturning is prevented using πpoverturn (keyframe ) and the robot starts to execute πpoverturn because of the priorities defined for skill selection. After overturning is prevented using πpoverturn (keyframe  ), the robot continues to execute πpslide. When the bowl reaches the desired position (keyframe ), the robot continues to execute πpslide. When the bowl reaches the desired position (keyframe  ), all failure risks are low, therefore the robot selects πstir to execute to complete the task. The robot executes πstir (key frames - ), all failure risks are low, therefore the robot selects πstir to execute to complete the task. The robot executes πstir (key frames - ) even though failure risks change but they do not increase significantly enough to activate risks. During the execution of πstir, the bowl starts to slide away and a particle is about to be spilled at the same time (keyframe ) even though failure risks change but they do not increase significantly enough to activate risks. During the execution of πstir, the bowl starts to slide away and a particle is about to be spilled at the same time (keyframe  ). The robot selects πpspill to execute because of the priorities defined for skill selection and prevents spilling. When the spill failure is prevented (keyframe ). The robot selects πpspill to execute because of the priorities defined for skill selection and prevents spilling. When the spill failure is prevented (keyframe  ), the robot executes πpslide to move the bowl to the desired position to reduce the risk and execute πstir to stir further. After 1000 steps(~50s) (keyframe ), the robot executes πpslide to move the bowl to the desired position to reduce the risk and execute πstir to stir further. After 1000 steps(~50s) (keyframe  ), the execution ends. As the summary of the execution, even though encountered risks, the robot does not overturn the bowl, does not spill any of the particles, tries to keep the bowl at the desired stirring location, and stirs the particles when it is suitable to stir. ), the execution ends. As the summary of the execution, even though encountered risks, the robot does not overturn the bowl, does not spill any of the particles, tries to keep the bowl at the desired stirring location, and stirs the particles when it is suitable to stir. |
We conducted additional evaluations for Evaluation of the Augmented Stir Skill, Adaptability to Novel Failures, Modularity vs Compound Skill, Reusability of Failure Prevention Skills over Different
Base Skills.
Evaluation results are given in the table above and the interpretation of the results are discussed below. The total
displacement of the particles in the bowl in meters (The Stir Reward), the number of the occurred spill events (Spill), the average position
difference of the bowl from the safe location in meters (Slide), and the number of the occurred overturn events (Overturn) are reported. The
upward arrow (↑) indicates that the higher is the better, and the downward arrow (↓) indicates that the lower is the better. F indicates fixed
bowl setup and U indicates unrestricted setup. Bold indicates undesired outcomes.
Evaluation of the Augmented Stir Skill
We first evaluate in the fixed bowl setup for benchmarking . Evaluation results indicate that πb stirs particles effectively while spilling occasionally. Then, our method is evaluated in the unrestricted setup . Comparing and , we can claim that the proposed method is significantly better for failure prevention with a tradeoff of stir efficiency. The loss of stir efficiency is tolerable as the environment of our method is more challenging and vulnerable to failures than the former. Therefore, it uses its time effectively to prevent any of the failures and stir whenever it is safe.
| πb-F |
L4-U |
 |
 |
For a fair comparison between our method and πb, the latter is also tested in the unrestricted setup . Comparing and , we see that our method is safer with a tradeoff of stir efficiency. Note that even though the number of spill events decreased for , one would not conclude that is safer than . Because in the unrestricted setup, forces affecting particles get diminished since a part of the force is transferred to the bowl, causing the number of spill events to decrease. Note that no overturn event is detected in the results because overturn failure occurs when the robot interacts with the bowl which only happens with . While this never happens for and ; successfully prevents overturn failure with .
Adaptability to Novel Failures
To show the adaptability of our method, we show how a robot working in the fixed bowl setup adapts its library to the unrestricted setup. In the fixed bowl setup, only spill failure can be observed since the bowl is fixed, and the skill library is formed with and . When restrictions on the bowl are removed from the environment, novel failures; sliding and overturning are observed, and and skills are learned to prevent them, respectively. Now the skill library is extended with these skills. When we compare and , it can be seen that with our method, it is easy to adapt to new conditions by discovering novel failures and learning corresponding failure prevention skills.
| L2-F |
L4-U |
 |
|
Modularity vs Compound Skill
One of the main questions that should be discussed is whether modularity helps with the failure prevention problem or not. For this investigation, a compound base-failure prevention skill is learned that takes into account all three failures during learning to stir and penalizes accordingly.
| L4-U |
πc-U |
|
 |
Comparing and , we can deduce that our method performs slightly better for the stirring efficiency, and the compound skill performs slightly better for failure prevention. However, when we compare the learned stir patterns of both methods, we see that does not perform a circular movement. It rather moves the spoon linearly in a narrow area resulting in only a slight change of particle locations which is not an effective stir. This performance degradation also supports the decrease in the average stir reward. Due to this linear pattern of movement, the probability of failures is smaller compared to . On the other hand, our further analysis shows that the modular method’s reward is highly dependent on how fast the prevention policy reduces the risk which explains the high standard deviation of the stir reward of and .
In the figure above, a randomly selected particle’s trajectories are given. Blue trajectory is from and orange is from .
Reusability of Failure Prevention Skills over Different Base Skills
To show the reusability of learned failure prevention skills, we set a case scenario on a different base skill, push, where an overturning failure may occur. The same skill which was previously learned for preventing an overturning failure for stir is included in the library. We have observed that by using the same risk estimation model, the robot can detect the risk of overturning and prevent the failure by using this skill. An example execution trace is given below.

Note that skill can successfully augment different actions (stir and push in our case). However, some skills may not be reusable and specific to the base skill or the manipulated object. For example, for , stir pushes the bowl from the inside to fix the position. This skill is reusable for container type objects but it may not be useful for other types. The robot may need to experiment with the utilities of failure prevention skills for different situations. We leave a broader analysis of the reusability of prevention skills as future work.
Transfer to the Real World
In this work, we directly transfer and parameters from the simulation to the real world. However, we use domain adaptation for the rest of the parameters that can not be represented directly.
| πb |
πpslide |
 |
 |
| πpoverturn |
πpspill |
 |
 |
Bibtex
@article{ak2023,
author={Ak, Abdullah Cihan and Aksoy, Eren Erdal and Sariel, Sanem},
journal={IEEE Robotics and Automation Letters},
title={Learning Failure Prevention Skills for Safe Robot Manipulation},
year={2023},
volume={8}, number={12}, pages={7994-8001}, doi={10.1109/LRA.2023.3324587}}
}